What is training data? Training data is information that is used to teach a machine learning model how to make predictions, recognize patterns or generate content. After an algorithm processes a vast amount of data, they are considered to be “trained,” and usable for many applications.
In practice, the trainingdata set often consists of pairs of an input vector (or scalar) and the corresponding output vector (or scalar), where the answer key is commonly denoted as the target (or label).
Training data is also known as training dataset, learning set, and training set. It's an essential component of every machine learning model and helps them make accurate predictions or perform a desired task.
AI training data are sets of examples used to teach machine learning algorithms to identify patterns and make predictions. In machine learning, training data consists of input features (observable characteristics) that are connected to output targets or labels in supervised learning scenarios.
In this article, we’ll explore why trainingdata matters, how tools like Encord are transforming data annotation, and how you can accelerate your AI projects with cutting-edge automation. Read on to learn how to turn raw data into actionable insights and scalable AI solutions.
AI trainingdata refers to the information used to teach machinelearning models and artificial intelligence systems how to recognize patterns and make predictions. This data is much like a textbook for students. If the material is clear, accurate, and complete, the “student” (your model) will learn effectively.
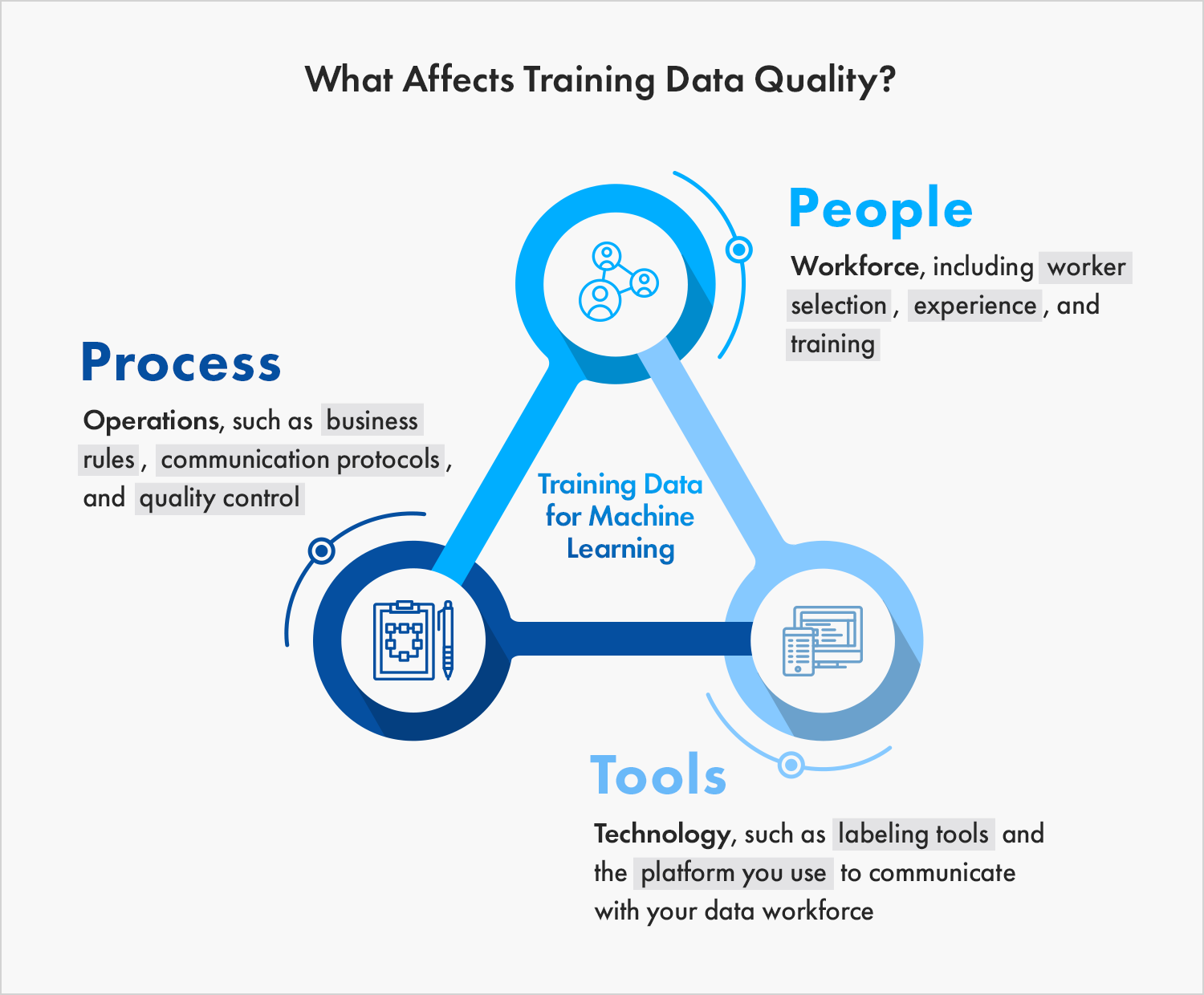 Training data is crucial for machine learning success. This guide covers everything you need to know to ensure your machine learning data is top quality.
Training data is crucial for machine learning success. This guide covers everything you need to know to ensure your machine learning data is top quality.